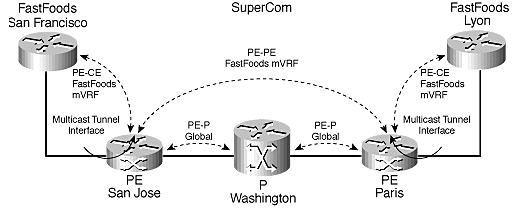
There are three way to provision Inter-AS connectivity:
1. Option A: Inter-AS Back-to-Back VRFs (PE to CE concept).
2. Option B: Inter-AS VPNv4 Exchange (using eBGP).
3. Option C: Inter-AS VPNv4 Exchange between Route Reflectors.
All three options support VPNv4 and VPNv6 prefixes
1. Option A (Back-to-Back VRFs)
– One logical/physical interface per VRF in the interconnection
– One PE-CE eBGP/IGP session per VRF between ASBRs
– Each ASBR thinks the other ASBR is a CE
– IP traffic between ASBR, no labels

Advantages:
– Most secure, least invasive, support granular QoS
– No need for common RDs/RTs between ASNs
Disadvantages:
– A VRF for each customer, not scalable
– An eBGP session per VRF, not scalable
– No label switched between ASBR
2. Option B (MP-eBGP between ASBR for VPNv4)
– One physical/logical interface for all VRFs in the interconnection
– PE-ASBRs exchange routes directly using eBGP
– PE-ASBR exchange VPNv4 prefixes + labels using MP-eBGP with the advertising ASBR as the Next-Hop
– ASBR-ASBR link must be directly connected, could use GRE tunnel-considered directly connected
– VPNv4 prefixes and IGP PE prefixes are exchanged between ASBR
– Filter to redistribute only the peer’s address
– Filter Vrfs with “no bgp route-target filter all” command on the PE’s

Advantages:
– Less invasive than Option C
– More scalable than option A for high number of VRFs
– No VRF needed, less configuration when the number of customers grow
– Single MP-eBGP sessions between ASBR instead of multiple eBGP (per VRF)
– More secure then option C because internal IP for the SP are not exchanged, the SP only exchange labels VPN prefixes.
Disadvantages:
– More invasive than Option A
– Less scalable then option C because the PE-ASBR store all VPNs routes that need to be exchange
– Common RDs/RTs between ASNs (unless RT rewrite is used)
3. Option C (Multihop MP-eBGP between RRs, VPNv4+Labels)
– One physical/logical interface for all VRFs in the interconnection
– eBGP session between ASBRs with directly connected interfaces
– Two Options for Label Distribution for BGP NH addresses:
IGP + LDP or eBGP IPv4 + Labels
– ASBR exchange PE loopback address and labels
– Route Reflectors exchange customers VPNv4 prefixes over multihop MP-eBGP
– Packets have three labels
– Next-hop-unchanged on each VPNv4 RR for the eBGP session

Advantages:
– Separate VPNv4 and PE prefixes exchange, most scalable option
– The ASBR does not need to know the customers VPN prefixes. The ASBR is only used to exchange the SP internal IP.
Disadvantages:
– Internal IP (Loopback IP for PE) addresses a SP network is advertised and visible in another SP network, which is a security risk. Most SP wants to prevent any external visibility and access into their internal LSR IP.
– Because of the above property, option C is mostly deployed within a single SP or enterprise with multiple MPLS networks (i.e. merger).
– Common RDs/RTs between ASNs (unless RT rewrite is used)
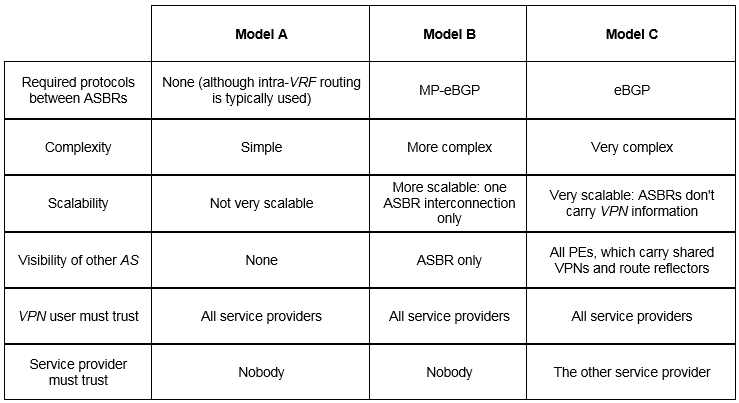
- Some decision guidelines, from a security perspective:
• If the number of shared VPNs and prefixes is small, consider model A. And it is the most secure option
• If you are peering with another operator, that is, the other AS is not under your direct control and you cannot fully trust it, use model B. Model C is not recommended here.
• If you are a single operator controlling all involved ASs, feel free to use model C. In this case, all your ASs behave a bit like a single AS, where ingress and egress PEs are in direct contact.
BRKMPL-2105 I-AS MPLS Solutions